IMDB Dataset
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import math
matplotlib.style.use("ggplot")
%matplotlib inline
plt.rcParams['figure.figsize']=(16,10)
Pour cette étude j’ai utilisé les données provenant de la plateforme de notation IMDB qui regroupe une large communauté notant les films et les séries
movies = pd.read_csv("./data/movie_metadata.csv")
movies.head()
| color | director_name | num_critic_for_reviews | duration | director_facebook_likes | actor_3_facebook_likes | actor_2_name | actor_1_facebook_likes | gross | genres | ... | num_user_for_reviews | language | country | content_rating | budget | title_year | actor_2_facebook_likes | imdb_score | aspect_ratio | movie_facebook_likes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Color | James Cameron | 723.0 | 178.0 | 0.0 | 855.0 | Joel David Moore | 1000.0 | 760505847.0 | Action|Adventure|Fantasy|Sci-Fi | ... | 3054.0 | English | USA | PG-13 | 237000000.0 | 2009.0 | 936.0 | 7.9 | 1.78 | 33000 |
| 1 | Color | Gore Verbinski | 302.0 | 169.0 | 563.0 | 1000.0 | Orlando Bloom | 40000.0 | 309404152.0 | Action|Adventure|Fantasy | ... | 1238.0 | English | USA | PG-13 | 300000000.0 | 2007.0 | 5000.0 | 7.1 | 2.35 | 0 |
| 2 | Color | Sam Mendes | 602.0 | 148.0 | 0.0 | 161.0 | Rory Kinnear | 11000.0 | 200074175.0 | Action|Adventure|Thriller | ... | 994.0 | English | UK | PG-13 | 245000000.0 | 2015.0 | 393.0 | 6.8 | 2.35 | 85000 |
| 3 | Color | Christopher Nolan | 813.0 | 164.0 | 22000.0 | 23000.0 | Christian Bale | 27000.0 | 448130642.0 | Action|Thriller | ... | 2701.0 | English | USA | PG-13 | 250000000.0 | 2012.0 | 23000.0 | 8.5 | 2.35 | 164000 |
| 4 | NaN | Doug Walker | NaN | NaN | 131.0 | NaN | Rob Walker | 131.0 | NaN | Documentary | ... | NaN | NaN | NaN | NaN | NaN | NaN | 12.0 | 7.1 | NaN | 0 |
5 rows × 28 columns
Dans un premier temps on peut commencer par faire un rapide descriptif des données fournies
movies.shape, movies.dropna(axis=0).shape
((5043, 28), (3756, 28))
movies.columns
Index(['color', 'director_name', 'num_critic_for_reviews', 'duration',
'director_facebook_likes', 'actor_3_facebook_likes', 'actor_2_name',
'actor_1_facebook_likes', 'gross', 'genres', 'actor_1_name',
'movie_title', 'num_voted_users', 'cast_total_facebook_likes',
'actor_3_name', 'facenumber_in_poster', 'plot_keywords',
'movie_imdb_link', 'num_user_for_reviews', 'language', 'country',
'content_rating', 'budget', 'title_year', 'actor_2_facebook_likes',
'imdb_score', 'aspect_ratio', 'movie_facebook_likes'],
dtype='object')
On ne garde, pour l’instant, que les lignes étant totalement fournies. On verra dans un deuxième temps comment remplir ces données manquantes.
Faisons quelques graphiques pour représenter ces données qui ne sont pas très parlantes pour l’instant. Pour cela on peut utiliser matplotlib, la librairie de référence pour les graphiques en python, mais j’aime bien utiliser seaborn qui permet très facilement de réaliser des graphiques assez attractifs.
Concentrons nous sur les notes attribuées par la plateforme.
fig, ax = plt.subplots()
movies.imdb_score.hist(bins=20, ax=ax)
ax.axvline(movies.imdb_score.mean())
<matplotlib.lines.Line2D at 0x18eef8cfcf8>
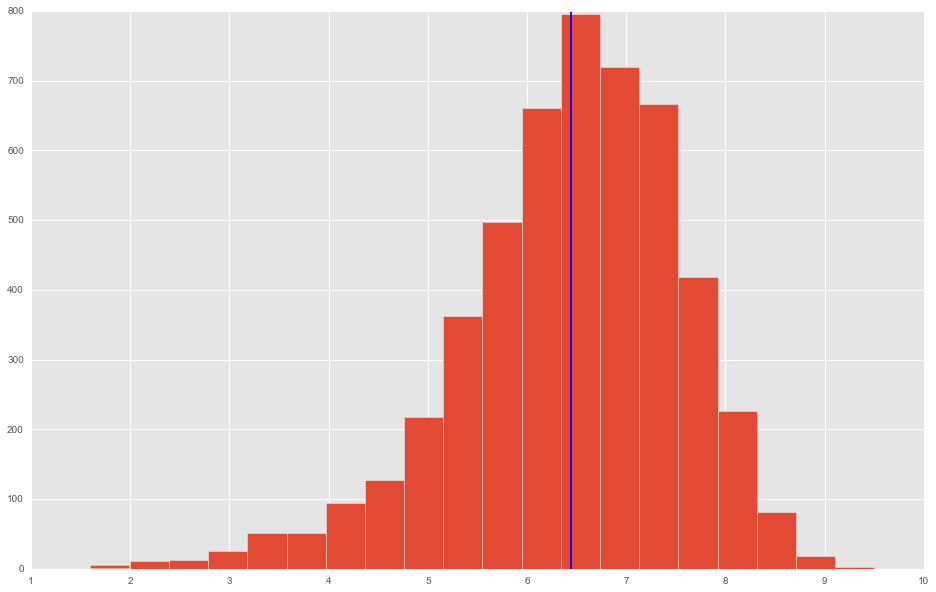
movies.imdb_score.mean()
6.442137616498111
On peut se poser la question de quelle serait l’année ayant fournie les meilleurs films. Pour cela on peut afficher la moyenne des notes en fonctions des années de sortie des films.
df_mean_by_year = movies.groupby("title_year", as_index=False).agg("mean")
sns.lmplot(x="title_year", y="imdb_score", data=df_mean_by_year)
<seaborn.axisgrid.FacetGrid at 0x18eef8d5978>
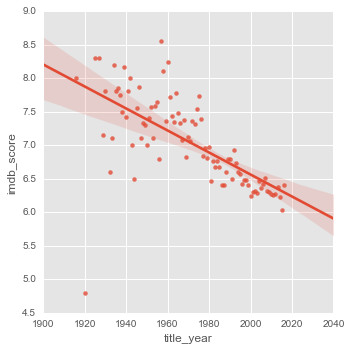
On voit très clairement un net dégradations des notes en fonctions des années.
movies["count"] = 1
movies.groupby("title_year").agg({"count":"count"}).plot()
<matplotlib.axes._subplots.AxesSubplot at 0x18eec199b38>
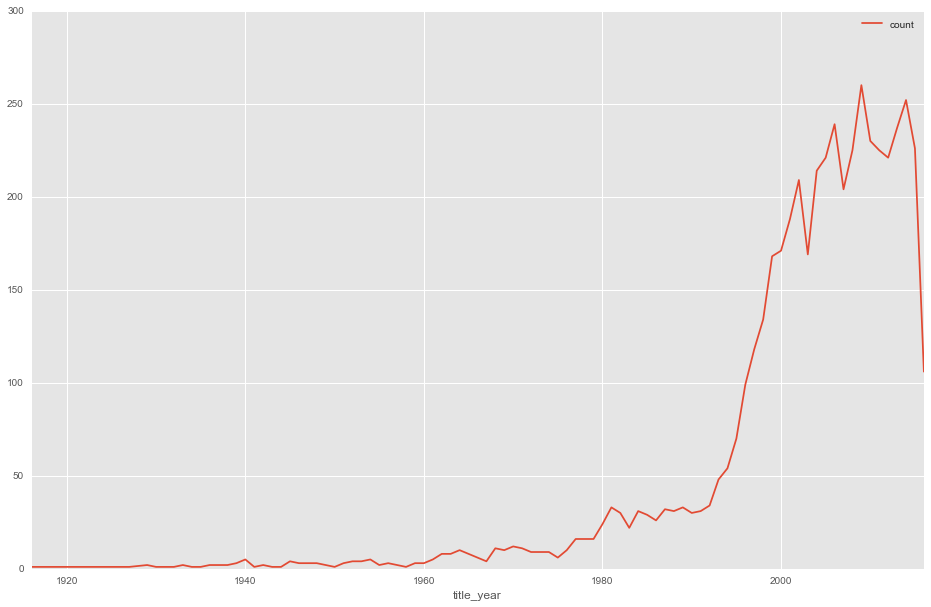
Mais le nombre de film à lui aussi très largement augmenté.
df_max_by_year = movies.groupby("title_year", as_index=False).agg("max")
sns.lmplot(x="title_year", y="imdb_score", data=df_max_by_year);
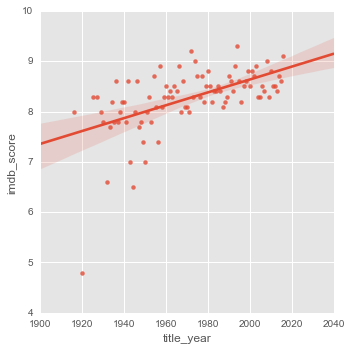
Mais les notes maximum attribuées sont légerement en hause. Mais quels sont les films les mieux notés de ces 100 dernières années ?
movies[~movies["director_name"].isnull()].sort_values("imdb_score", ascending=False).head(10)[["director_name", "movie_title", "imdb_score"]]
| director_name | movie_title | imdb_score | |
|---|---|---|---|
| 2765 | John Blanchard | Towering Inferno | 9.5 |
| 1937 | Frank Darabont | The Shawshank Redemption | 9.3 |
| 3466 | Francis Ford Coppola | The Godfather | 9.2 |
| 4409 | John Stockwell | Kickboxer: Vengeance | 9.1 |
| 2837 | Francis Ford Coppola | The Godfather: Part II | 9.0 |
| 66 | Christopher Nolan | The Dark Knight | 9.0 |
| 4498 | Sergio Leone | The Good, the Bad and the Ugly | 8.9 |
| 3355 | Quentin Tarantino | Pulp Fiction | 8.9 |
| 1874 | Steven Spielberg | Schindler's List | 8.9 |
| 4822 | Sidney Lumet | 12 Angry Men | 8.9 |
Quels genres préfèrent t’on ?
ax = sns.violinplot(x="genres", y="imdb_score",
data=movies, palette="Set2", split=True,order= list(movies.genres.value_counts().head(10).index),
scale="area", inner="quartile")
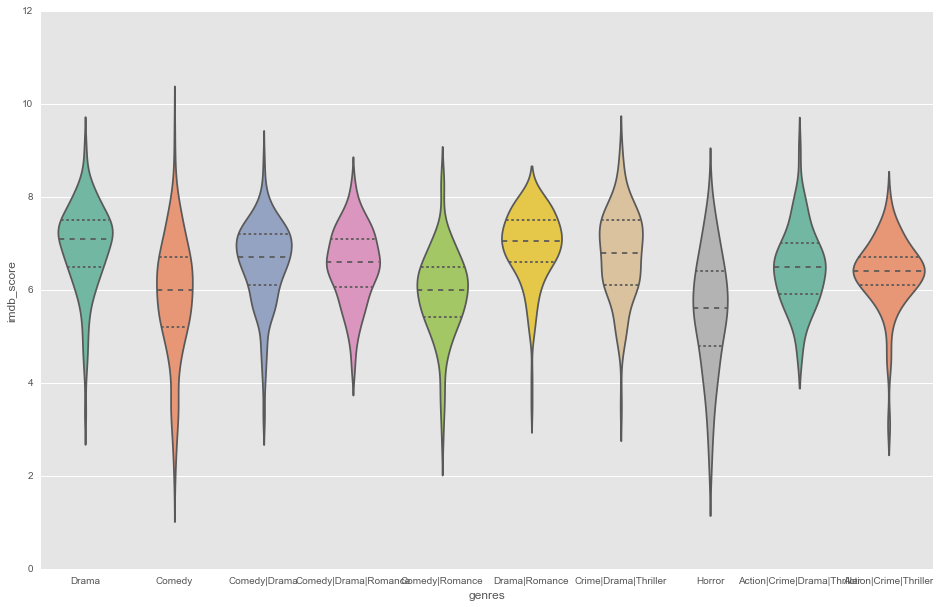
movies.groupby("genres").agg({"imdb_score":"mean","count":"count"}).sort_values("imdb_score", ascending=False).head(5)
| imdb_score | count | |
|---|---|---|
| genres | ||
| Action|Adventure|Crime|Drama|Sci-Fi|Thriller | 8.8 | 1 |
| Action|Adventure|Biography|Drama|History | 8.6 | 1 |
| Crime|Drama|Fantasy|Mystery | 8.5 | 1 |
| Adventure|Animation|Drama|Family|Musical | 8.5 | 1 |
| Action|Drama|History|Thriller|War | 8.5 | 1 |
Comment prédire le score IMDB
On voit assez bien que les notes sont plutot au dessus de la moyenne. On peut maintenant essayer de voir si on peut trouver une corrélation entre le nombre de like de chaque acteur et la note attribuée.
sns.jointplot(x="cast_total_facebook_likes", y="imdb_score", data=movies);
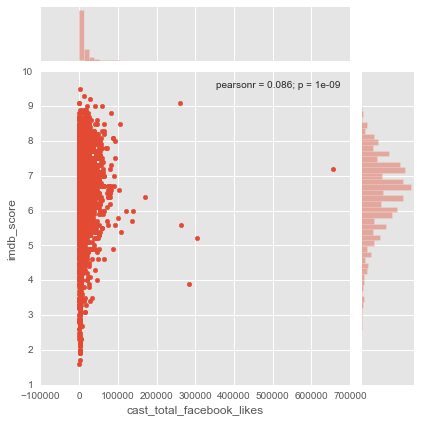
On voit ici que les données sont très écrasées autours de 0. On voit quelques points qu’on peut nommés d’outliers ce qui veut dire qu’ils sont vraiment éloignés de la plupart des autres points de l’échantillions.
Pour cela nous avons plusieurs solutions, les plus faciles à mettre en oeuvre sont de les enlever tout simplement ou d’appliquer un logarithme sur la variable en question. On sait par contre que le log n’est défini que sur ]0;+inf[ il faut prendre en compte cela dans sa mise en place.
movies["cast_total_facebook_likes_log"] = movies["cast_total_facebook_likes"].apply(lambda x : math.log(x) if x!=0 else x)
Si on réaplique le log sur cette nouvelle variable créée
sns.jointplot(x="cast_total_facebook_likes_log", y="imdb_score", data=movies);
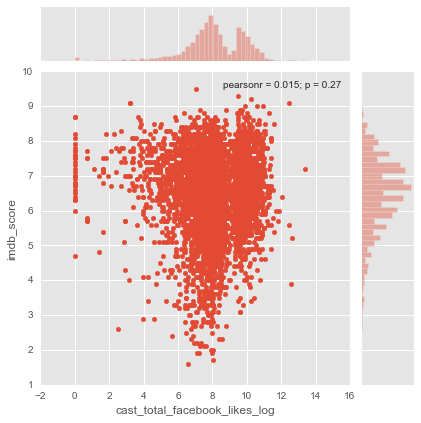
On voit que le nuage de point, ainsi que l’histograme ne sont plus écrasés en 0 mais nous ne pouvons malheuresement pas tiré de conclusions sur la création du score en fonction du nombre de likes de l’équipe du tournage.